


Retrieval-augmented generation (RAG) has made significant strides in enhancing the Language Model’s (LLM) ability to provide contextual and informed responses by leveraging external knowledge bases. The process chiefly involves an indexing stage to prepare a knowledge base, and a querying stage to fetch relevant context to assist the LLM in answering queries.
The inception of RAGA (Retrieval-Augmented Generation with Actions) augments this existing architecture by incorporating an action-taking step, thereby not just stopping at generating responses but proceeding to execute actions based on the generated information. This is a transformative step towards making AI systems more interactive and autonomous.
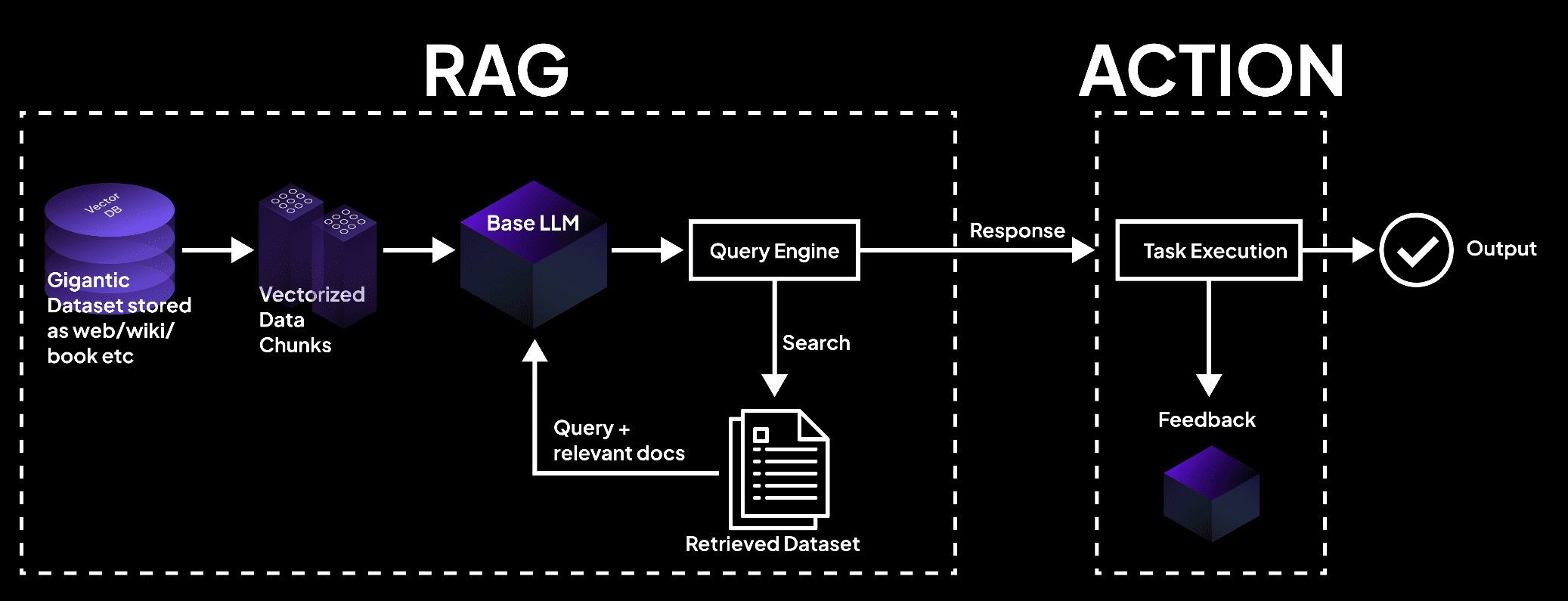
Understanding the RAGA Architecture
Expanding on the RAG framework, RAGA adds a critical third stage to the pipeline:
1. Indexing Stage: Similar to RAG, this stage involves preparing a knowledge base using data connectors to ingest data from various sources into a Document representation.
2. Querying Stage: This stage fetches the relevant context from the knowledge base to assist the LLM in synthesizing a response to a user query. The LlamaIndex facilitates the retrieval and indexing of data, ensuring accurate and expressive retrieval operations.
3. Action Stage: This is the new addition to RAGA. Post the generation of responses, this stage is responsible for taking appropriate actions based on the insights derived from the generated responses.
Action Determination: Based on the generated response, the system determines the action that needs to be taken. This could be defined through predefined rules or learned through reinforcement learning techniques over time.
Action Execution: Once the action is determined, RAGA executes it. This could range from sending a notification, adjusting a setting in a system, interacting with other software or hardware components, to even making decisions that affect a broader workflow.
Feedback Loop: Post-action, the feedback, if any, is collected to refine the action-determination process. This loop helps in improving the accuracy and relevance of actions over time.
Exploring a use-case: Sending highly personalized emails
Let’s illustrate how RAGA can be applied to a use case where an email marketer needs to send out highly personalized emails to a list of people.
Step 1: Retrieval
Data Collection: RAGA begins by collecting relevant data for personalizing emails. This data can include recipient profiles, historical interactions, preferences, and any other relevant information.
Knowledge Base Preparation: The collected data is organized into a knowledge base, using data connectors and indexing tools similar to those in the RAG framework.
User Query: The user specifies the goal, such as “Send personalized emails to this contact list.”
Step 2: Querying
Context Retrieval: RAGA retrieves context from the knowledge base to assist LLM in personalizing the emails. It fetches information like recipient names, past interactions, recent activities, preferences, etc..
Query Formation: The system generates queries to retrieve the relevant data from the knowledge base, e.g., “Retrieve recent interactions with John Doe” or “Retrieve preferences of Mary Smith.”
Response Generation: Using the retrieved context, RAGA generates personalized email content for each recipient, incorporating their name, recent interactions, and preferences. It may also craft subject lines and email bodies tailored to each individual.
Step 3: Action
Action Identification: The LLM identifies the action to be taken, which is to send out personalized emails to the respective recipients.
Action Formulation: The LLM converts the generated email content into machine-readable email templates.
Communication with Email Service: The LLM communicates with an email service or client, filling in the templates with recipient-specific details and sending the emails.
Feedback Collection: After sending the emails, the system collects feedback, such as delivery notifications or recipient responses, to evaluate the success of the action.
The addition of the action stage in the RAGA architecture opens up a lot of possibilities, from automating personalized email campaigns to providing seamless customer support via AI Agents. It reduces human intervention, streamlines processes, and learns from its actions, making AI systems more efficient and adaptable for real-world applications.
If you’re a developer building out LLM-powered applications and just discovered RAGA, here’s a quick guide to selecting the best method amongst RAG, RAGA, and Fine-tuning based on your application’s use case and other key metrics.

Source: https://superagi.com/introduction-to-raga-retrieval-augmented-generation-and-actions/