


The quality of output generated by AI agents is limited by LLM constraints such as information cutoff & lack of quality data for niche tasks, which can fail to deliver context-rich, domain-specific outputs. However, by integrating knowledge embeddings, AI agents can enhance their depth and accuracy, ensuring that their responses are not only factually correct but also rich in contextual nuance.
Knowledge embeddings are vectorized data from file sources like Docs, PDFs, CSV, etc. stored as vector representations within a multi-dimensional space. By encapsulating semantic relationships and patterns in the data, these embeddings are converted into dense vectors, making them amenable for processing by machine learning models.
When integrated with autonomous agents powered by LLMs, knowledge embeddings can significantly enhance the agent’s ability to reason, provide accurate responses, and generate more contextually relevant content by grounding the model’s response and outputs in structured, factual knowledge. This synergy can lead to more informed and reliable autonomous AI agents. Let’s see how SuperAGI users can use knowledge embeddings to improve agent outputs.
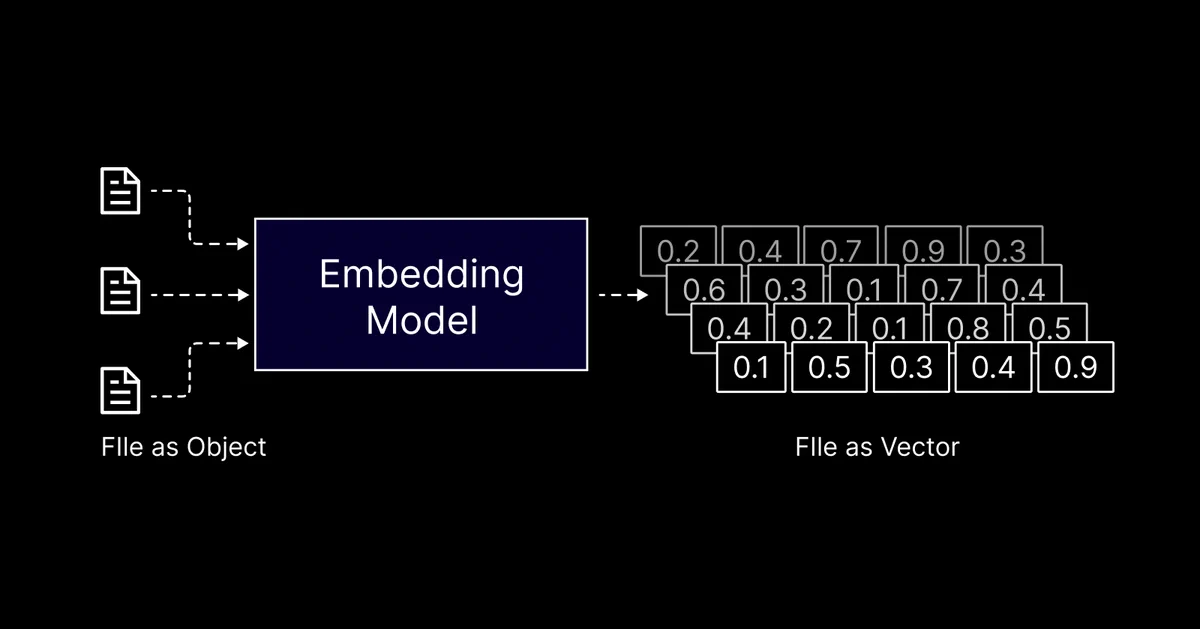
Understanding Knowledge Embeddings with an Example
Consider an AI agent tasked with managing social media campaigns. By integrating an ‘SEO keyword knowledge embedding’, the agent can refine the quality of the campaign content. Instead of only automating posts, the agent can now generate content around important SEO keywords. This results in more relevant, high-quality content that drives better engagement.
Integrating Knowledge Embeddings into SuperAGI
Knowledge Embeddings can be used in SuperAGI by plugging it into an agent workflow, providing the agent with contextual knowledge to operate with an understanding of their tasks. Through user-configured knowledge, agents can access this group of information, optimizing their efficiency and output quality.

How can agents access Knowledge Embeddings?
Agents can access the Knowledge Embeddings with the help of the “KnowledgeSearch” Tool by running a semantic search query, unlike traditional keyword-based search systems.
When presented with a query, it shifts through the embeddings, identifying and returning information that has the highest semantic similarity to the input query. This ensures that the data retrieved is not only relevant but also contextually aligned with the agent’s objectives. Currently, SuperAGI is compatible with OpenAI’s text-embedding-ada-002 model.
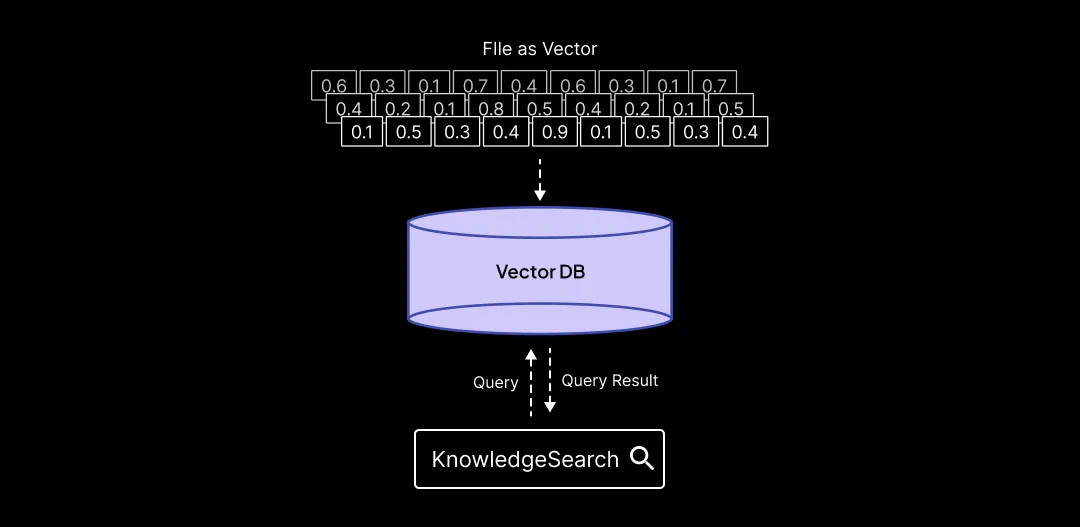
Integrating Custom Knowledge
Users can integrate their custom knowledge with SuperAGI as follows:
Database Configuration: Users initiate by setting their vector database and index URL within SuperAGI. Knowledge Integration: Options are available to either procure knowledge embeddings from the marketplace or incorporate external knowledge sources. Agent Setup: Creation of an AI agent, the ‘KnowledgeSearch Tool’ and the relevant ‘Knowledge Embedding’ are selected for optimal performance.

Creating & Hosting Custom Knowledge Embeddings SuperAGI allows users to install pre-existing embeddings from the marketplace or integrate their custom knowledge embeddings hosted on Pincecone, Qdrant, or Weaviate. Here’s how you can host and integrate your custom knowledge embeddings via all 3 of these vector DBs:
- Qdrant Vector DB:
Access your Qdrant Account
Navigate to the dashboard, create a new cluster, or access existing clusters.
Get your api-key, and URL to create a client instance.
To create your index, run the following code with your Qdrant Credentials.
Once your index is created, go to Vector Settings in SuperAGI by clicking the settings icon on the top right corner.
In the Vector Database Settings, select Qdrant.
Add your vector database settings and click connect. This will connect your Qdrant index.

- Pinecone:
Login to your account on Pinecone.
You can create an index as follows or can use an existing index
Input the index name and add 1536 in dimensions. For knowledge embeddings, we use OpenAI’s text-embedding-ada-002 model which creates embeddings of 1536 dimensions.
After the index is created, go to Vector Settings in SuperAGI by clicking the settings icon on the top right corner.
In the Vector Database Settings, select Pinecone
To connect Pinecone, add the API Key, environment, and index name.
Go to the Pinecone dashboard and click Indexes to get the index name
Go to the Pinecone dashboard and click API keys to get the API key and environment.
Add these in Vector Database settings and click Connect. This will connect your Pinecone index.

- Weaviate:
Access your Weaviate Account.
Navigate to the dashboard, Create your cluster for Weaviate, or access existing clusters.
Get your API-key, and URL from cluster details.
To create your class run the following code with your Weaviate Credentials.
Once your class is created, go to Vector Settings in SuperAGI by clicking the settings icon on the top right corner.
From Vector Database Settings, select Weaviate.
Add your vector database settings and click connect. This will connect your Weaviate class.
